Optimizing SQL Query Performance: Tips and Insights
Relational database systems are slow, especially when you have a million data or executing complex queries.
Sometimes we end up performing multiple joint processes just to retrieve some data. The more tables we joined, the slower response time we got.
Writing a proper query and paying attention to the database design is a good practice to improve the query performance.
In this article, I will discuss query performance tuning.
We will discover how the query works, why it became slow, how the database handles its performance issue, and what could we do to solve this problem.
What makes my SQL query slow?
- Bad query.
Selecting more fields than what we need, performing unnecessary sorting or grouping, and not using filters, are some examples of bad queries that could perform slows. - Large data.
Scanning a hundred data to find a specific product is fine. But scanning billions of data to find it, is a problem. - Bad database design.
Using the wrong datatype, for example, storing a Number as a String could impact our query performance. Because every time we need to calculate the number, we must do casting, which will add more cost to the query.
Understand how SQL queries work.
Before we can write a good query, we must understand how the query works and how the database engine executes the SQL statement we give.
Each database system has its way of handling SQL statements. But most of the processes are similar. This is how the Oracle database handles SQL statements.

The process is composed of 4 steps. SQL Parsing > Optimization > Row Source Generation > Execution.
- SQL Parsing
The database parse SQL statement into a data structure that he can understand and process. These steps include:
Syntax check. The database checks if there is a wrong syntax. e.g. from misspelled as form.
Semantic check.
It determines whether a statement is meaningful. For example, it will check if there is a nonexistent table or column in our statement.
Shared pool check.
The database will generate a hash value for every query. When a new SQL statement is submitted, it will look up into a stored statement that has the same hash value. If a suitable query plan is found, it will skip the next processing step and execute the query. This is called soft parsing.
But if there is no match query plan, it will continue the SQL processing and generate a new one. This is called hard parsing. - Optimization
The query optimizer will generate an execution plan (query plan). An execution plan is details of how the SQL statement will be executed.
It will consider factors such as indexes, table statistics, and database configuration to determine the most efficient way.
This process also includes join order optimization and parallel operation possibilities.
This process will produce an execution plan with the lowest cost estimation.
Take a look at this query. (This query is a PostgreSQL query, I don’t have any Oracle database installed. But it is okay, the execution plan concept is similar.)
select
order_items.order_id,
order_items.product_id,
products.product_category_name,
order_items.price
from
order_items
join products
on products.product_id = order_items.product_id
where
products.product_weight_g > 200
and order_items.price > 40
order by
products.product_category_name ascThis is the query plan (execution plan) created.
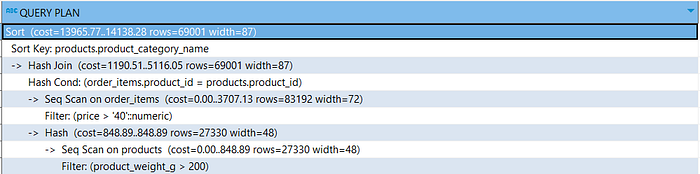
- Row Source Generation.
Based on the execution plan, the row source generator will generate a more specific instruction to execute the execution plan. - Execution.
The SQL engine will execute each step from the row source generator plan from the bottom to the top. Then it will return the final result.
That is how SQL processing happened on the Oracle database. Again, it may differ slightly among other database systems, but the main concept and process are similar.
How do we measure the query performance?
To understand the query performance, we have to do query profiling.
Query profiling is a step in analyzing a query to understand how the query is executed, including the cost and performance impact.
This time I will do query profiling on the PostgreSQL database.
We could use the ‘explain’ and ‘explain analyze’ statements to do the profiling.
Using explain:
explain
select
*
from products
where
product_category_name in ('perfumaria', 'instrumentos_musicais','cool_stuff')Result:

Using explain analyze:
explain analyze
select
*
from products
where
product_category_name in ('perfumaria', 'instrumentos_musicais','cool_stuff')Result:
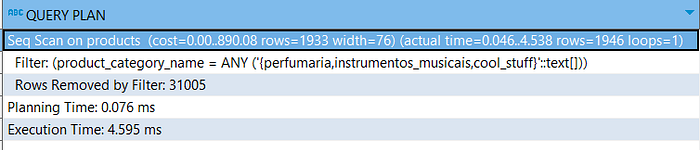
Take a look at the following things:
- Planning time: Time spent to generate the query plan.
- Execution time: Time spent to execute the query plan.
- Cost: Estimation cost used by the query optimizer, calculated based on the row number and resource use.
- Width: The size of data returned by the process.
- Loop: How much loop is performed over rows in the table.
Comparing those things could help to decide whether your query is optimized enough or not.
Through the query plan execution stats, you can find out which process is heavy and try to find a solution to reduce that process.
Another way to do profiling in PostgreSQL is by using pg_stat_statements.
This is an extension for PostgreSQL that will capture all the SQL statements executed and show its performance stats.
The result is more complete than using an explain statement, but you may need some configuration before you can use it.
Using pg_stat_statements:
select * from pg_stat_statements;Result:

With pg_stat_statements, you could monitor your query and evaluate its performance.
Understand more about the Query Optimizer.
Most relational databases have a Query Optimizer. Looking back at the SQL statement processing steps, Query Optimizer takes part in generating an optimal query plan.
During the statement parsing process, Query Optimizer may devise an alternative way from what we declared on our SQL statement.
Take a look at the following example. I have 2 queries, both different, but do the same thing.
-- Using sub query
explain analyse
select *
from order_items
where order_items.product_id
in ( select product_id from products where product_weight_g > 1000)
-- Using join
explain analyse
select order_items.*
from order_items
join products
on order_items.product_id = products.product_id
and product_weight_g > 1000Each query should return all order_items where the product_weight_g is greater than 1000.
The results:
Based on the query, we may assume that there is a difference in execution ways or different performance. But if we execute it using the explain analyze statement. You will realize that the queries generate identical query plans.
- Using sub-query (query plan)
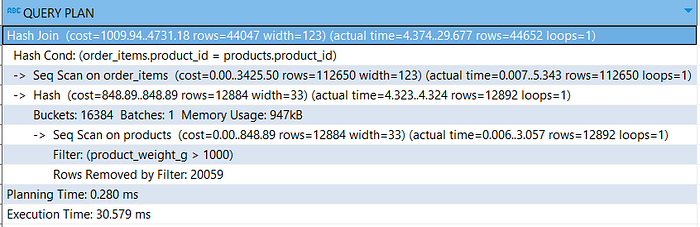
- Using join (query plan)
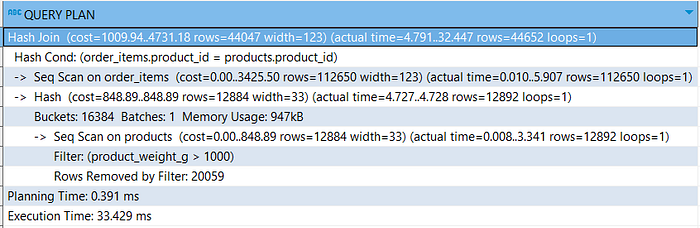
What happened? As I said before, during the SQL statement parsing process, the query optimizer may find a better approach to execute the queries. Instead of using subquery, it's more efficient to use the hash join method.
What makes understanding the query optimizer and the query plan important?
We are not the one who controls how our query will be executed, the query optimizer is. Knowing this will prevent us from doing unnecessary SQL performance tuning that only wastes time.
In my experience, I have written a lot of queries and invested more time in thinking about it. But when I did query profiling, I was shocked that my ugly query had no performance improvement than the regular one. All I see is just an ugly SQL query.
Another thing that I would like to share is how I wrote this article. Before I start, I read several books about SQL performance tuning tips. Some of those tips are very convincing and make sense. Take a look at the following tips:
- Avoid using subquery
- Ordering join tables statement starting with the smallest to the largest
- Put the most restrictive conditions in the where clause last statement because the query plan is executed from the bottom
- Using Union is faster than using the OR statement
- Use IN instead of the OR statement
All the tips are look good, but not worth it. Query optimizer could optimize sub-query, as we see in the previous example. It could change the join order based on the database statistic. The IN and the OR statements are executed in similar ways, so there is no performance difference.
Still, do we have to optimize our query? Despite we know that our query optimizer handles this thing by default?
Yes, we have to. As long as the query slows, you should do something. Don't just think about writing a good query, try to help your query optimizer produce the best query plan.
Tips to optimize your SQL Query Performance.
- Use index.
This is a classic solution, but always works.
An index is a data structure that is associated with a table. Instead of scanning the entire data, the database could scan the index and find the desirable data faster.
Let’s compare some queries, the first one will not use an index, but the second one will use it.
This is the SQL statement I would like to execute.
explain
analyze
select * from products where product_category_name = 'perfumaria'This is the execution result when the product_category_name column is not indexed yet.
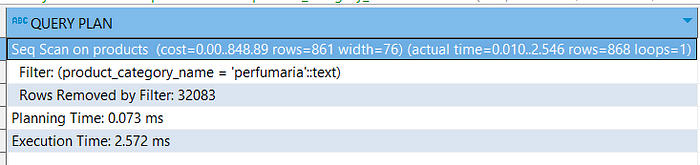
Now let’s add an index to the product_category_name column.
CREATE
INDEX products_product_category_name_index
ON products (product_category_name)Re-run the SQL statement. This is the result I got.
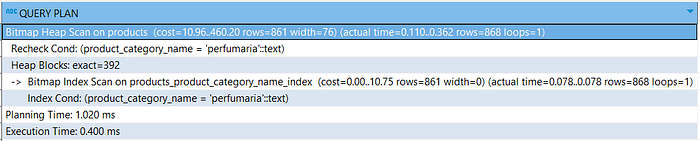
2.572ms vs 0.400ms, the execution time on the indexed column is way faster.
The index is powerful, but you have to use it wisely. Nothing comes without a cost.
Here are some tricks on using Index.
- The primary key is indexed by default. Most databases automatically add an index for the primary key column.
- Use index for columns that are foreign keys, frequently used to join tables, or frequently used as conditions on query.
- Don’t use an index for a small table. Using indexes requires more resources like CPU and memory. It adds more cost to the process. If your table is small enough, scanning all data may become more efficient instead of using an index. Take a look at the previous query with the index example, the execution time is way faster, but the cost is also higher.
- Don’t use an index for columns that are frequently updated.
The index is slowing down your insert, update, and delete operation. Why? Because every time you modify the data, the index must be updated. That’s why adding an index on the column that is frequently updated is not a good idea, because it will always update the index. While the indexes are on update, your table will be locked and no operation can be performed.
2. Avoid using functions on indexed columns.
Don't use SQL functions on indexed columns, it will prevent the query optimizer from using your index.
Let’s compare the following queries.
-- Using index
explain
analyze
select * from products where product_category_name = 'perfumaria'
-- Using upper functions on an indexed column
explain
analyze
select * from products where upper(product_category_name) = 'PERFUMARIA'
-- Using concat functions on an indexed column
explain
analyze
select * from products where concat('"',product_category_name,'"') = '"perfumaria"'These are the results:
- Using index

- Using upper functions on an indexed column

- Using concat functions on an indexed column
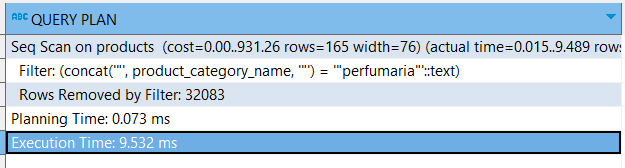
See? The functions are preventing your query optimizer from using indexes. The query optimizer has to do a full table scan instead, and of course, it’s slower.
If we need to cast or convert the column value, we could convert the parameter instead. For example:
-- Using upper functions on an indexed column (Modified)
explain
analyze
select * from products where product_category_name = lower('PERFUMARIA')
-- Using concat functions on an indexed column (Modified)
explain
analyze
select * from products where product_category_name = replace('"perfumaria"', '"', '')Results:
- Using upper functions on an indexed column (Modified)

- Using concat functions on an indexed column (Modified)
Now the query optimizer could use the index again and the operation performs better.
3. Never retrieve data more than you need.
Loading more data requires more resources. Compare these queries.
-- Select *
explain
analyze
select * from products where product_category_name = 'perfumaria';
-- Select specific columns
explain
analyze
select product_id product_category_name, product_weight_g
from products where product_category_name = 'perfumaria';Results:
- Select *
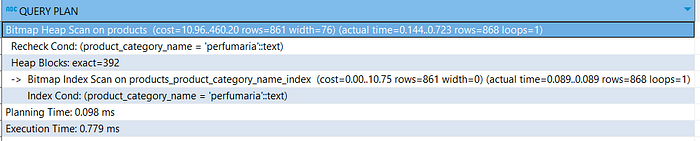
- Select specific columns
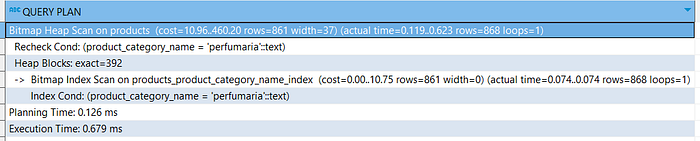
The cost is equal and the execution time is close. This happens because the database has to access the entire columns to retrieve the selected columns.
Now take a look at the final width. 76 vs 37, the select statement on specific columns returns a smaller width. Smaller width means smaller data size loaded to your application.
This will reduce the amount of data transferred over the network and the amount of memory used to store them. Limiting the number of columns may not make your query faster, but it does improve your application performance.
If you want a faster query, you should limit the number of rows returned. You can limit the data by adding conditions on the where clause statement and joining conditions.
It will help to query optimizer generate a better query plan. The rows will be filtered first before it goes to the next process.
3. Use SQL parameter bindings.
Parameter binding is a good way to prevent SQL injection, and also a good way to optimize our SQL performance.
Database memorizes our query plan, this is part of the query optimization process.
Every time we give the same query, it won't parse it again, instead it will use the existing query plan. The planning time became faster.
But when the query has a hard-coded parameter and it always changes, the query optimizer would think that the query is fresh and need to be parsed. Then we are going to have some extra planning time.
Take a look at the following example.
-- Without parameter bindings
select * from products where product_id = '0009406fd7479715e4bef61dd91f2462';
-- With parameter bindings
set @product_id = '0009406fd7479715e4bef61dd91f2462';
select * from products where product_id = :product_id;
The first query will generate a new plan every time the product_id changes. The second query won't because the query is handled separately from the parameter values.
Be aware of how your database handles parameter bindings.
Let me tell you an interesting fact, some databases will handle your query binding automatically.
For example, PostgreSQL handles your query-binding as a part of its query optimization.
If I run this query, then I check the PostgreSQL query stats.
-- Without parameter bindings
select * from products where product_category_name = 'perfumaria';
-- Check the postgresql stats monitor
select * from pg_stat_statements
where query like 'select * from products where product_category_name%';This is what I got.

PostgreSQL automatically replaces the product_category_name with the ‘$1’ sign. Good for us.
One thing you should remember. Not all databases did the same thing.
For example, MySQL didn’t support binding parameters.
If we want to achieve the same things, we should use a prepared statement.
prepare sql_statement from 'select * from products where product_id = ?';
set @product_id = '0009406fd7479715e4bef61dd91f2462';
execute sql_statement using @product_id;
deallocate prepare sql_statement;It’s important to understand the power of your database and use it to improve your performance.
4. Avoid sorting and unnecessary heavy process.
Some SQL operations are heavy and expensive. Sorting, grouping, distinct statements, and joining on the large table, are heavy.
Take a look at the comparison below. I have 3 queries, sorting on an indexed column, sorting on an un-indexed column, and without sorting.
-- Sort on indexed column
explain analyze
select * from products order by product_category_name asc
-- Sort on un-indexed column
explain analyze
select * from products order by product_weight_g asc
-- Without sort
explain analyze
select * from productsResults:
- Sort on indexed column

- Sort on un-indexed column
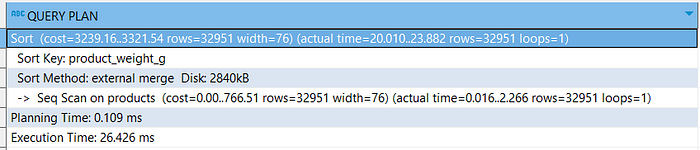
- Without sorting

Of course, the query without any sorting process will run faster.
It runs 3 times faster than a query with sort on indexed column, and 8 times faster than a query with sorting on un-indexed column.
The index also has a good impact on improving the query performance when there is a sorting process.
But again, putting indexes everywhere is not a solution.
Knowing the impact of your SQL process and using it correctly is a better approach.
For example, you write a query to download all your data for analytical purposes.
You don't have to use sorting, since what you need is raw data with all the related. So don't use sorting.
Know what you need, and use the proper queries to achieve it.
5. Watch your query plan.
When your query goes wrong and gives a performance issue, the first thing you should do is watch your query plan.
Take a look at the plan steps, and see if there is a heavy task. See the execution time. How many rows are returned from each process, the cost, and the width of the data?
No solution perfectly suits every problem. Always evaluate your query plan and find the proper solution to improve your SQL performance.
Thanks for reading my article. Leave a clap if you like it.
Please feel free to point out any errors you may come across.
Reference:
